The 8 Most Important Statistical Ideas: Bootstrapping and Simulation-Based Inference
A dinner party with friends, a vending machine, and magic… Or how bootstrapping allows us to estimate the distribution of almost anything without complicated equations or gathering many samples. Featuring a very cool interactive widget.
This article is the second in a series of posts where I discuss the 8 most important statistical ideas of the past 50 years, as reviewed by Gelman & Vehtari (2021). Today’s concept is bootstrapping and simulation-based inference.
Introduction to the series: The 8 Most Important Statistical Ideas
The last 50 years have seen important advancements in the field of statistics, shaping the way we understand and analyse data. Gelman & Vehtari (2021) reviewed the 8 most important statistical ideas of the past 50 years.
I was curious about the eight ideas, so I decided to write about them to deepen my understanding. Hopefully someone else finds it useful~
How to Get Data from the Entire World and Not Die Trying
Picture this: you’re having dinner with nine friends and someone has the brilliant idea of comparing screen times. You all take out your phones and share how many hours per day you spend staring at your screen. There are surprises and laughter.
Someone asks: “What’s the world’s average screen time?”. One friend says that’s a stupid question: “we could calculate our mean, but the entire world’s? There’s no way to know”. Somebody suggests: “maybe we can extrapolate from our data?”.
This is a common problem in statistics: we have a sample of data (the measurements from our friends) and we want to estimate the distribution in a population.
The population is an abstract idea: it represents all the individuals we are interested in. In our case, the entire world. In other—more realistic—cases, it could be all students in a country, all bears in a specific mountain, or all grapevines in a vineyard.
Before going any further, let’s think about what a sample is.
Where Do the Samples Come From? Gashapon!
Are you familiar with these machines?

It’s a type of vending machine called gashapon in Japan. You insert coins, turn the knob, and you get a random something1.
Imagine a huge gashapon with 8 billion capsules, each representing a person in the world. Each capsule has a number inside: that person’s screen time. All those capsules are the population.
When we shared the screen times at the dinner party, we were, in a way, taking ten capsules form this machine. The numbers we got are our sample.
Statistical Inference
We have one sample. Now what? Let’s use statistical inference: a set of tools to generate insights about the population from a sample.
Traditionally, before doing any math, we would need to assume a particular distribution (shape) for the population. For example, a “normal distribution”:
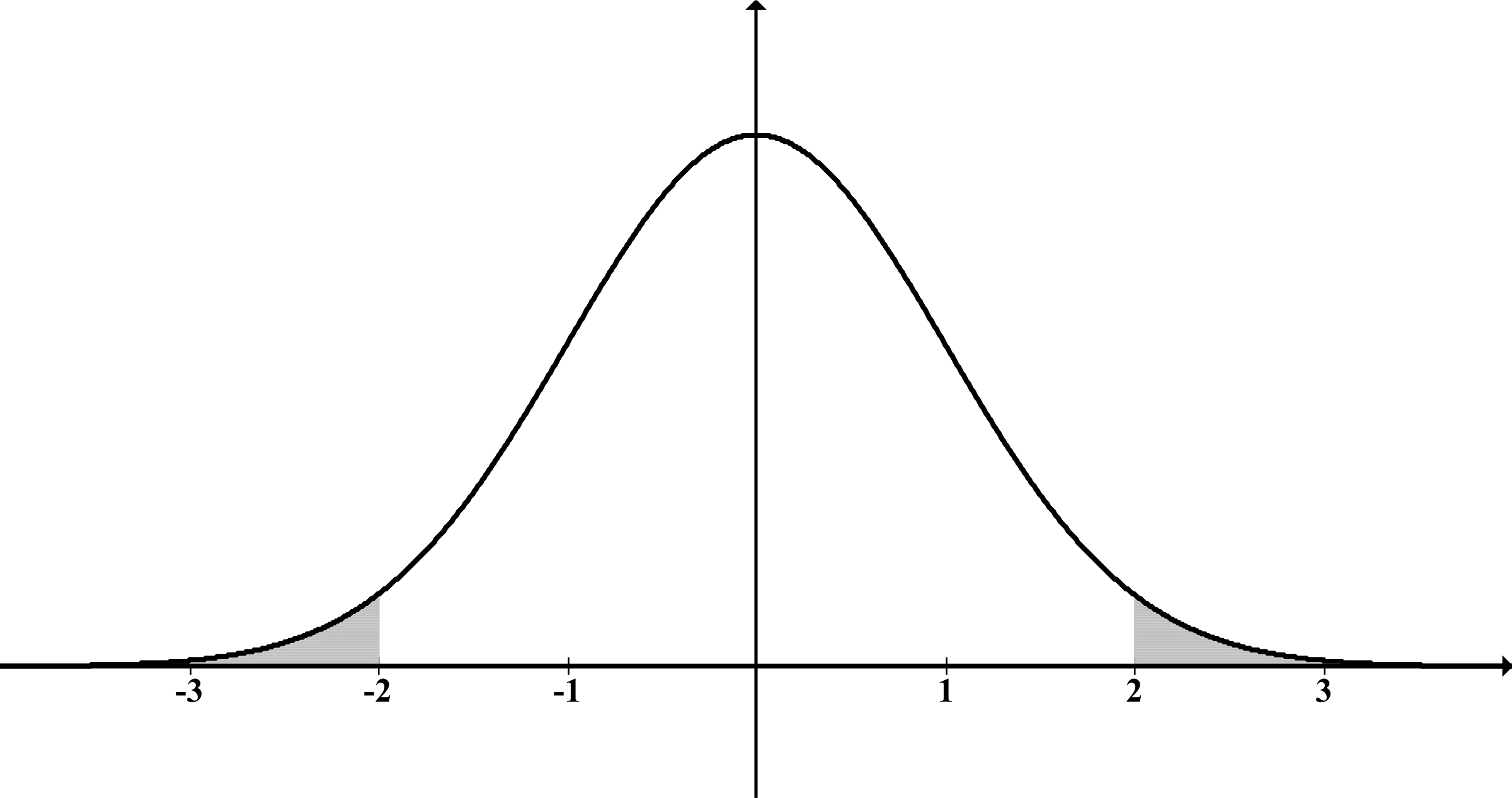
As you can see, it’s symmetrical around the mean (the tallest point in the graph). That means there are as many values above the mean as there are below it.
But what if screen time is asymmetric? This could very well be the case, considering ~15% of the population does not own a smartphone.
There are cases where we can’t or don’t want to assume a particular distribution for the population. Luckily, there’s an alternative for those situations.
Simulation-Based Inference
Simulation-based inference uses simulated samples to make predictions from a single sample. Some examples of this approach are bootstrapping, Markov Chain Monte Carlo methods, permutation testing, and simulation-based calibration.
Let’s explore what’s perhaps the purest example of simulation-based inference: bootstrapping.
Bootstrapping: Gashapon, Remixed
Remember the huge gashapon with 8 billion capsules? We (metaphorically) took ten capsules from it to get our original sample at the dinner party. Let’s grab those capsules and place them into a new, normal-sized, gashapon.
The new gashapon has our original sample and a new feature: a shuffle button to mix the capsules.
Let’s use this machine to generate our first bootstrapped sample. We’ll need to:
- Take a capsule and write down the number.
- Put the capsule back in the machine and hit shuffle.
- Repeat steps 1 and 2 until we have written down ten numbers.
That’s it! The ten numbers we have written down are our bootstrapped sample. Simple enough, no?
Notice how we’re putting the capsule back into the machine this time. This is called sampling with replacement. It means that we can get the same number more than once. Also, since we’re shuffling them, all capsules have the same probability of being picked, every time. This makes each draw independent, just as if we were drawing from the 8-billion-capsules machine.
Why, Though?
The key idea (and assumption) is that we consider our original sample to be a reasonable approximation of the population. Thus, the bootstrapped samples reflect the variability and characteristics of the population.
In short: generating bootstrapped samples ≈ sampling from the population.
As you might have guessed, a single bootstrapped sample is not very useful. Typically we’ll need anywhere between 50 and 10,000 bootstrapped samples. To achieve this, we use computers to repeat the process many times.
Give It a Try!
I’ve built a small gashapon simulator based on our example. On the first row you’ll see our original original sample: the screen time of each friend at the dinner party.
When you press the “Create one bootstrapped sample” button, your device will go through steps 1 to 3 described above and show you the ten chosen capsules.
Notice how each bootstrapped sample is unique: a capsule can show up more than once—or not at all—and each sample has a different mean. Go ahead and try it!
Original sample • Mean = ? hours
Last bootstrapped sample • Mean = ? hours
Histogram of bootstrapped means
95% confidence interval: ?-?
The histogram above shows a bar for each mean you’ve generated. The bar’s height represents the number of times a particular mean has appeared. You can interact with the bars to see the mean and count they represent.
Did you get a bar on the histogram? That’s the mean of the original sample. Was it the tallest bar in your experiment? It often isn’t.
Below the histogram you can find some statistics about the bootstrapped means, including the 95% confidence interval. This is the range of values where we would expect the population mean to be. From your current results, we would conclude the world’s average screen time is between ? and ? hours.
Did you notice how the confidence interval changed as you generated more samples? As the number of bootstrapped samples grows, the confidence interval becomes more stable.
Every time you press “Start over”, the original sample changes. You’ll need some luck for this, but see what happens if your original values are asymmetric (for example, most numbers being below the mean): how does that affect the histogram’s shape?
It’s Not Magic Though — Limitations
You might have thought something like “what if our friends all hate phones and have zero hours of screen time (or are all addicted)? Wouldn’t we be assuming the entire world is like that?”. You’re right; this is one of the limitations of simulation-based inference. In short: since we treat the original sample as the population, it better be representative. If it’s skewed, our confidence interval and conclusions will be as well.
The other big limitation explains the arguably disappointing results: “The world’s average screen time is between 5 and 12 hours? That’s not very precise.” Indeed. Getting an accurate estimate from such a small sample size would be closer to magic than statistics.
The larger our original sample, the narrower the confidence interval. If we had 100% of the population data, the interval would just be a single number: the true population mean (e.g. “4-4”). The less data we have, the less confident we can be in the predicted values, resulting in wider intervals.
Conclusion
In this post we’ve learnt about simulation-based inference through bootstrapping.
Bootstrapping allows us to estimate the distribution of almost anything without needing to gather more samples from the population and without making assumptions about the distribution of the data, unlike traditional statistical methods.
One big advantage of bootstrapping is that it can be applied in almost all situations without complicated mathematical equations. However, it’s important to remember the two main limitations: the sample size and its representativity.
Another great thing about this technique is that it’s not limited to means; bootstrapping is just the process of generating the synthetic samples. Thus, we can use the bootstrapped samples to calculate the median, mode, standard deviation, correlation, reliability coefficients, or even the effect size2!
How cool is that?
Next up in the series we’ll be learning about overparameterised models and regularisation. See you soon!
Learning Resources
Video: Bootstrapping Main Ideas!!! — StatQuest (2021). Josh Starmer has a great introduction to bootstrapping on his YouTube channel StatQuest. Can’t recommend his channel enough!
Academic paper: The frontier of simulation-based inference — Cranmer, Brehmer & Louppe (2020). This article explores different simulation-based inference methods in light of recent advances in machine learning and offers some recommendations as to which approach to choose.